:::
科技新知

多模態AI結合具身智慧發展趨勢
發表日期:2025-01-22
作者:林研詩(工研院)
摘要:
多模態人工智慧(Multimodal AI),是指同時利用各種類型(包括文字、圖像、影片、語音…)或模態的資料形成洞察、做出預測和產生內容的人工智慧系統。
全文:
一、AI浪潮下,模型持續進化成多模態AI以擴大垂直應用
多模態人工智慧(Multimodal AI),是指同時利用各種類型(包括文字、圖像、影片、語音…)或模態的資料形成洞察、做出預測和產生內容的人工智慧系統。多模態AI模型與大多數AI模型不同在於,一般大型語言模型(LLM) 僅處理文字資料,而卷積神經網路(CNN) 模型處理影像資料,亦即多數AI模型只能處理單一模態的資料。而近期AI科技公司Google、NVIDIA、Meta、OpenAI等正開發各項多模態AI技術,以期未來可將技術投放至醫療保健、協作機器人…等各垂直領域應用。因多模態AI模仿了人類固有的理解世界的方法,若能將視覺、聲音和觸覺等感官輸入資料結合起來,整合到一個模型中,形成對現實環境更細緻的感知,AI系統將可更全面地了解環境,並創造百工百業AI人機互動新模式,例如使用多模態AI開發新的醫療診斷工具、或賦予機器人具身智慧(Embodied AI),使其可更理解環境與互動,從而產生更類似人類的行為和能力等。
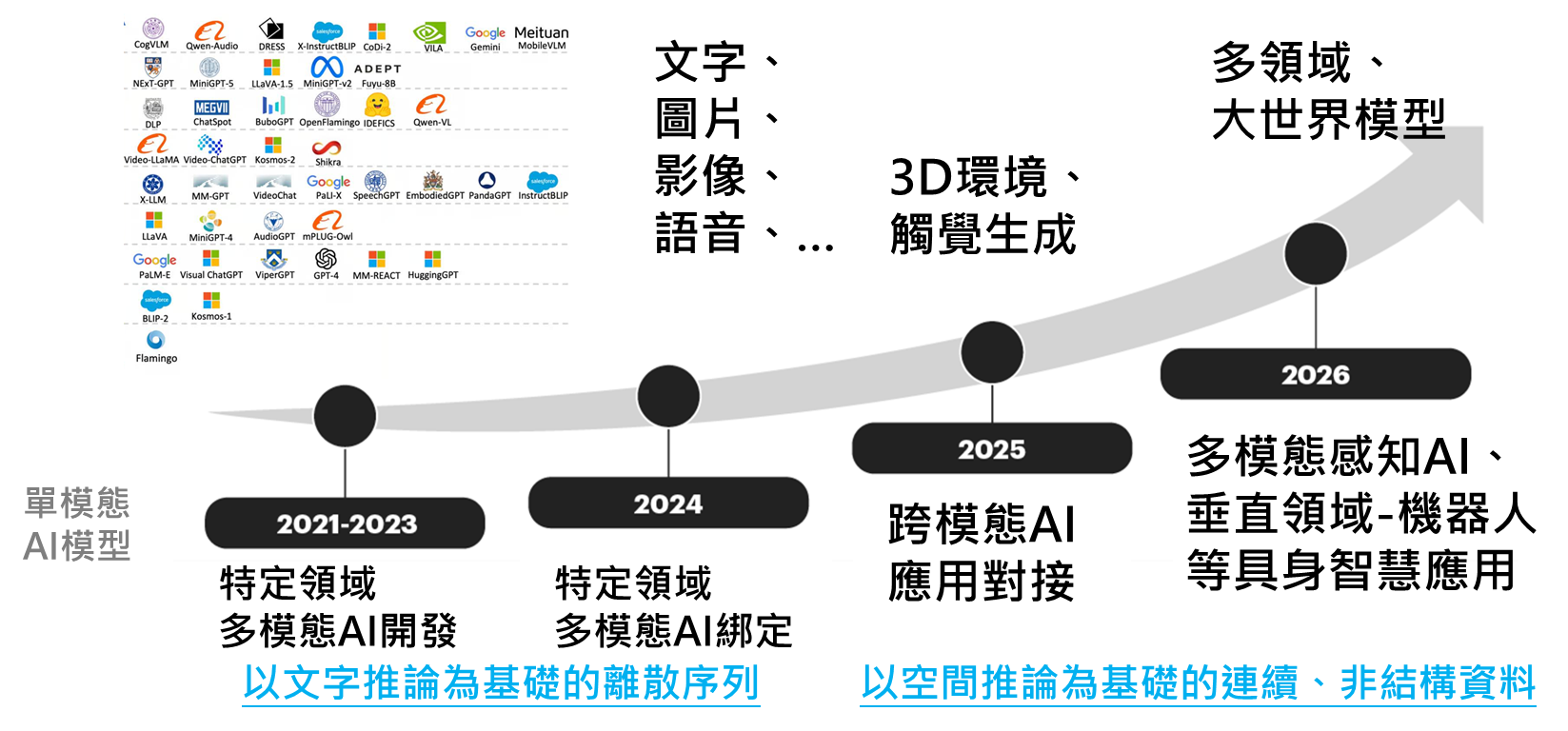
資料來源:工研院產科國際所 ITIS研究團隊(2025/01)
圖1 多模態AI模型進化歷程
以下針對近期指標大廠與新創公司投入多模態AI技術的發展進行綜整:
二、大廠與新創布局多模態AI結合具身智慧的潛在商機
(一)科技大廠開發AI機器人訓練平台與建立系統架構
1. NVIDIA開發人形機器人通用AI基礎模型
NVIDIA 開發人形機器人通用AI基礎模型,稱為 Project GR00T計畫,目標為建立一個全面的多模態AI平台,推動機器人技術和AI具身智慧領域的突破,朝通用人形機器人基礎模型邁進,以期為機器人打造可理解自然語言的大腦,並透過整合機器視覺,觀察人類行為,讓多模態AI可快速自主學習,提高機器人的協調性、靈活性和多項技能。目前此AI 平台已提供給 1X Technologies、Agility Robotic、Apptronik、波士頓動力、Figure AI、Fourier Intelligence、Sanctuary AI、Unitree Robotics 和 XPENG Robotics 等先進的人形機器人公司測試使用。Project GR00T詳細內容包括:算力來源採用NVIDIA Thor系統單晶片(SoC),此晶片是基於 NVIDIA Blackwell 架構的圖形處理器(GPU),其 Transformer 引擎提供具有 800 兆次浮點運算的 8 位元浮點等級 AI 效能,可運行 GR00T 等多模態生成式 AI 模型。該算力主要提供模組化的Jetson Thor人形機器人運算平台以及NVIDIA Isaac一系列機器人模擬生成式 AI平台、強化學習能力的 Isaac Lab 與運算協作服務 OSMO等執行複雜任務的能力,並整合機器人預訓練、資料庫和參考硬體,提供安全、自然地與人機互動模式。
2. TESLA正大規模地在車輛、機器人等領域部署AI自主運作系統
TESLA積極地開發多模態感知人形機器人,基於自身已具有先進視覺AI和路徑規劃能力基礎,以及全自動輔助駕駛的晶片(FSD)設計經驗,進一步開發人形機器人,使其具備自動化操作的能力,以及多模態自主學習能力,例如可透過觀看影片持續學習、進化。目前TESLA所展示的第二代人型機器人Optimus 2,高約 173 公分、重約 56 公斤,行走速度每小時 8 公里,可搬運重物或輕握雞蛋,旨在提高製造產線的工作效率和安全性,並能處理複雜的環境情境。TESLA多模態神經網路可實現完全端到端運行,透過視覺捕捉的影片資料以及具有11 個自由度(DOF)的靈巧手提供觸覺感測器數據,直接產生關節控制序列。這樣的設計使得單一神經網路可以透過添加多模態資料進行訓練,並產生自發性的校正與執行多項任務。TESLA計劃2025年將少量生產1,000個人形機器人,在美國TESLA工廠執行產線工作。
3. Meta建立多模態資料的共同嵌入空間與訓練,讓機器像人可全局分析
Meta在2023年推出結合文字、聲音與視覺資料的多模態開源AI模型ImageBind,整合了六大感知模態,包括照片/影片、文字、聲音、深度、熱量與慣性測量單元(IMU)。目的是讓機器能夠像人類一樣,全面分析不同類型的資料,並可用聲音或影像資料生成影像,或以聲音生成影像,創造更豐富、更像人類的AI模型,未來更朝多模態應用整合,例如觸覺、嗅覺,或是大腦的功能性磁振造影(fMRI)訊號等。在AI領域中,隨著模態數量的增加,缺乏不同的感知數據會限制標準的模態學習,但Meta將不同模態資料嵌入共同空間,讓多模態AI模型學習各種模態與訓練。Meta在2024年推出多模態Llama 3.2開源模型,並持續精進語音辨識準確度,回答更準確、更有深度的內容,未來有望整合應用到終端產品中,例如Meta Ray-ban智慧眼鏡。此外,Meta基礎AI研究團隊(FAIR)與南加大研究團隊近期共同發布Transfusion多模態模型訓練技術,綜合轉換器模型(Transformer Model)和擴散模型(Diffusion Model)的優勢,同時具有離散數據的處理能力以及連續數據的生成能力,使單一模型即可同時處理文字與圖像數據,成為全新的多模態學習方法。
4.Google開發多元用途機器人AI訓練模型
Google知名的Gemini 模型是以語言為核心,並在此基礎上整合感知層面的聲音、視訊和影像,利用多模態Transformer 架構,處理多種模態數據,提升AI模型的推理和理解能力。多模態資料輸入包括文字、圖像、聲音和視訊的交錯序列,並可輸出交錯的圖像和文字回應,然後把多模態資料聯合後再次重新訓練,包括文字、圖片、聲音、影片等,遵循next token prediction 的模式,即是將所有模態的資料先變成隨機詞元(token),最後變成一維線性輸入,讓模型可預測next token,這種方法可把多模態資料在預訓練階段進行整合。此外,Google在2023年3月發布的多模態PaLM-E模型,是可應用於具身智慧的語言模型,能夠不再依賴文字輸入,而是訓練語言模型直接取得機器人感測器資料的原始數據,再輔以大量網路圖文資訊訓練而成的RT-2(Robotic Transformer 2)模型,讓機器人可將複雜指令分解成簡單指令,更能理解與執行未知任務,以及搭配視覺-語言-動作(vision-language-action,簡稱VLA)模型進而讓AI機器人產生動作,已有人形機器人公司Figure AI採用此方式進行訓練。
5. Apple Inc. 展示多模態AI訓練框架
Apple與瑞士洛桑聯邦理工學院(EPFL)合作開發多模態AI模型(Massively Multimodal Masked Modeling)訓練框架,簡稱4M-21模型,為一種any to any視覺AI模型,可支援21種模態任務和模態,例如人類姿勢和體形等。相較於傳統視覺機器學習模型只能用於特定領域的模態或任務,近期大語言模型則進化成具備多模態識別能力,而4M-21則是更進一步的多模態AI模型訓練方法,透過遮罩建模(masked modeling)方法,訓練出多模態的統一編碼、解碼模式(Transformer encoder-decoder),讓輸出、輸入都可支援多模態資料,包含文字、圖像、語義模態,以及現有藝術模型DINOv2和ImageBind的神經網路特徵地圖等。此種多模態AI模型亮點在於具備未經微調(out-of-box)即有極佳的視覺識別效能、可操控(any-conditional & steerable)生成、跨模態擷取、支援多種感測器與資料混合的能力,並且以很少量的token訓練並有效擴充以訓練模型,未來對於開發桌面或家用機器人等具有應用潛力。
(二)AI獨角獸新創公司整合多模態AI朝通用機器腦邁進
1. OpenAI-以AI模型訓練外包公司的人形機器人開發:OpenAI自從推出 ChatGPT 之後,其在全球的影響力迅速上升,除主要投資者微軟已斥資 100 億美元對其進行投資外,OpenAI 在 11 輪融資中總共募得 1,350億美元資金,目前市場估值已超過 300 億美元。OpenAI將機器人開發外包給Figure AI、1X 和 Physical Intelligence 等公司,近期與人形機器人獨角獸公司Figure AI(B 輪融資投資者包括微軟、OpenAI、NVIDIA 和貝佐斯等,共籌了 6.75 億美元,估值約 26 億美元)合作推出Figure 02人形機器人,依托OpenAI 的大模型,可以利用獨立的神經網路,接收人類指令、與人類流暢對話、理解人類的意圖,並執行向人類傳遞蘋果、整理垃圾、放置餐具的動作,並可解釋為何這麼做。另一間OpenAI投資合作的挪威新創機器人公司1X Technologies,近期推出一款專為家庭設計的人形機器人原型—NEO Beta,展示出基於影片生成(Sora)AI和自動駕駛世界模型(端到端自動駕駛,E2EAD)的AI模型進展,1X最新開發的人形機器人世界模型,可作為通用機器人的學習模擬器,使機器人可以在自己創建的空間中執行規劃、評估和模擬操作。由此可見,原本ChatGPT僅具備讀懂圖像和文字的能力,輸出內容還僅限於文字,但隨著OpenAI推陳出新,把以文生圖功能整併,再加上語音互動,將更多的多模態功能加進ChatGPT中,成為機器人的智慧大腦,將創造更多人形機器人的應用市場。
2. Skild AI-開發適應非結構化環境的通用機器AI模型:Skild AI為美國新創,由兩位卡內基美隆大學教授於 2023 年 5 月創立,至2024年7月A輪已募資3億美元,估值達到15億美元,投資者包括Bezos Expeditions、Coatue、Lightspeed Venture Partners、軟銀和General Catalyst、紅衫資本以及其他投資者。主要訴求為開發基於物理世界的智慧系統,構建機器人基礎模型。一般傳統機器人技術側重於收集特定資料,訓練機器人以完成特定任務,而Skild AI則利用多模態資料,透過基於 Transformer 的自我調整架構構建AI基礎模型,創建通用且具備湧現行為的機器人模型。由於具備此技術需要突破機器人資料壁壘,Skild AI稱其訓練模型的資料量「是競爭對手模型的千倍以上」,可作為通用機器人大腦,涵蓋操作、移動和導航等功能。目標市場包括可在惡劣環境中具備韌性的「四足機器人」,以及進行複雜家庭和工業任務的「人形機器人」,使機器人操作像呼叫 API 一樣簡單。
3. World Labs-開發空間感知大世界模型,解泛化機器人難題:World Labs由史丹佛大學AI科學家李飛飛與Jastin Johnson、Christoph Lassner 和 Ben Mildenhal於2024年4 月共同成立, 7 月即完成兩輪融資,投後估值超過10 億美元。投資方包括a16z、加拿大基金Radical Ventures 等知名創投。主要開發空間演算法(spatial intelligence),使AI機器人可理解真實物理世界並與之互動,市場定位在2025 年推出首款大世界AI模型(LWM),用於感知、生成 3D 世界模型並與之互動,可支援 AR 、機器人、自動駕駛服務等。空間感知技術可將圖像和文字推論到三維環境中,賦予機器人獲得「空間智慧」,即是借鑒人類視覺數據演算法,以及高級推論能力處理視覺數據、做出3D環境對應關係的預測,並根據這些預測採取行動,解決AI機器人與現實世界中的人類互動的問題。 World Labs正探索利用AI模型的能力,使AI機器人可理解口語指令,執行如開門和製作三明治等複雜任務。在AI機器人實現通用化(AGI)之前,建立這種空間「推論」能力至關重要。
三、多模態AI促成人形機器人先由製造業落地
目前已有多家公司提供場域,以合作試點(PoC)方式,進行人形機器人的測試。其中,多模態AI的整合技術扮演關鍵角色。例如車廠BMW在美國南卡羅來納州的斯帕坦堡工廠最新採用Figure 02機器人的資料擷取和訓練功能,內建視覺語言模型,搭配微軟H100 ND大型語言模型訓練、OpenAI資料自定義多模態模型進行微調,透過其中6個RGB相機提供(頭部2個,腹部4個)AI 視覺系統感知和理解物理世界,實現快速常識視覺推理,目前已可成功將車用鈑金零件插入特定的固定裝置中,然後將其組裝成底盤的一部分;TESLA則是運用多模態AI視覺學習資料庫,在自家電動車車廠測試Optimus人形機器人進行電池分裝,所有操作都在自行開發的車用全自動駕駛FSD晶片上即時運行,整合攝影機、手部觸覺和力感測器等多模態感知資料,Optimus可將電池單體精確地分類並插入托盤,以及自己修正錯誤;車廠Mercedes-Benz也開始測試 Apptronik公司的人形機器人 Apollo,進行車廠裝配的工作。
除了車廠外,全球領先的大型物流公司GXO Logistics正與兩家人形機器人公司合作,包括與Apptronik公司合作研發人形機器人,以及與另一家Agility Robotics公司簽署長期部署協議,使用其旗下Digit 機器人和Agility ArcTM雲端自動化平台,專為倉儲物流工作而設計,協助人類完成各種重複性任務。
除了製造與物流業外,先前義大利羅馬醫院與研究機構 Fondazione Santa Lucia IRCCS也評估使用 Oversonic公司開發的神經復健人形機器人RoBee,可解釋環境、人類情緒和反應並相應執行任務,協助患者和醫護人員進行神經復健、溝通和認知評估。此類人形機器人在醫用人機互動領域和新型社交機器人具有發展潛力。如下圖所示,多家人形機器人公司投入各垂直應用產業,未來也將在建築業、防災救助領域等實現補充勞動力缺口的應用情境。
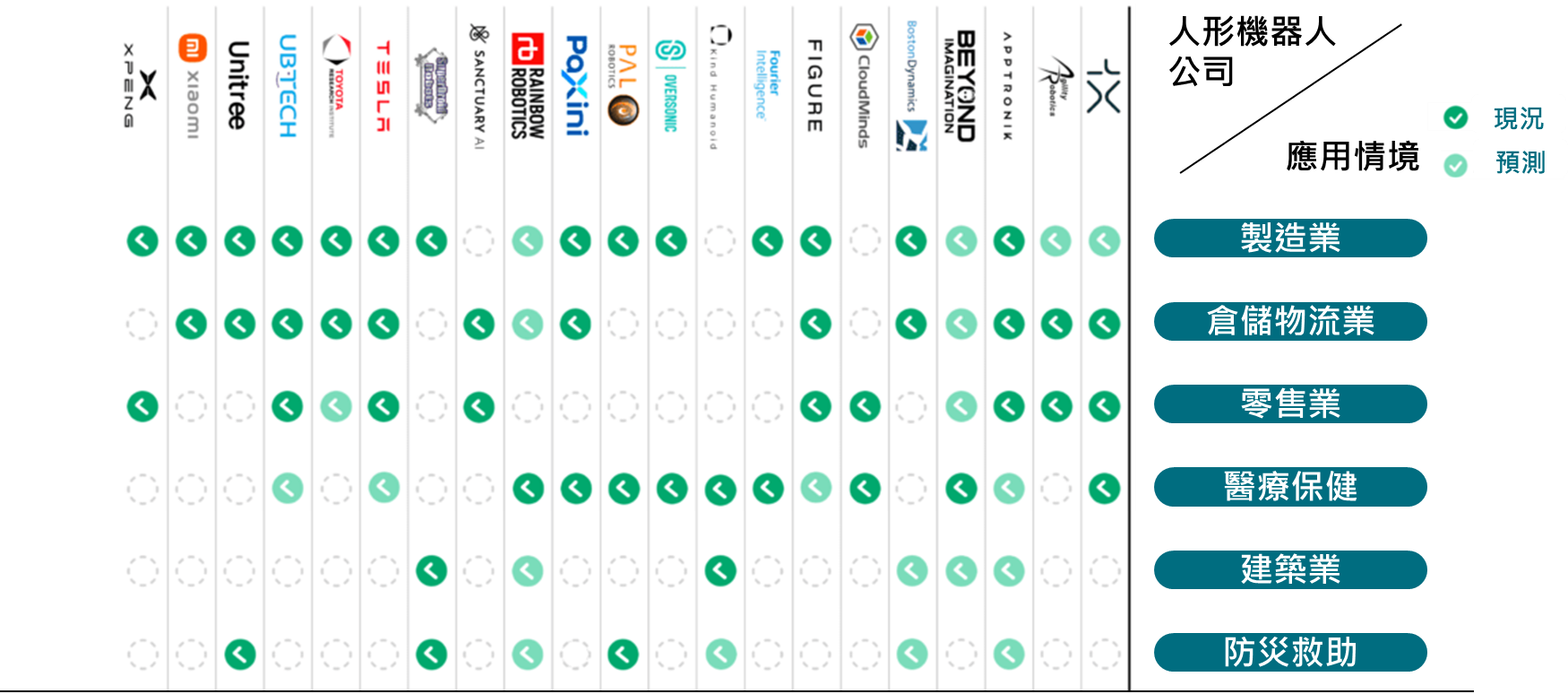
資料來源:CB Insights (2025/01)
圖2 多模態AI人形機器人六大潛力應用情境
四、結論
(一)多模態模型開發帶來具身智慧自動化代理以及應用服務商機
根據Gartner調查,在2023年生成式AI方案多模態應用僅佔1%,但預估至2027年約有40%生成式AI方案將為將多模態應用,能處理文字、圖像、聲音、影片等不同資料型態,市場需求包括特定垂直領域的模型,以及自動化代理服務等。目前仍在多模態AI應用的創新啟動期,預計接續文字、影音生成後,下一波為整合觸覺模態AI模型,例如目前已有澳洲新創TouchGPT公司將觸覺感知整合至到模態AI模型中,未來可透過嵌入在智慧終端的感測器,訓練AI系統學習觸覺,將有機會應用於遊戲、機器人、醫療等各領域。隨著多模態AI模型賦能機器人更多處理複雜任務的能力,機器人將具備整合多種感官資料(視覺、聽覺、觸覺等)的學習能力,成為具身智慧實現工廠自動化與人類的得力助手,開啟新「智械時代」人機互動方式,即多模態AI機器人即服務(Multimodal AI Robot-as-a-Service)市場。
(二)跨多模態機器人AI模型仍需克服多項挑戰
包括如何同時有效處理多個數據流,實現不同模態資料的對齊與融合,並識別出不同模態之間的關聯,以及將多模態資料整合在單一的模型中,是實現AI機器人多模態推論能力的關鍵。目前多模態模型需要配置多個子網絡或模組,這不僅增加了模型的複雜性,也顯著提升了訓練和推理的算力成本。未來開發方向除了搭配更有效的數據訓練、高質量合成數據、輕量化資源運用、雲地整合技術、70億參數規模以下的小模型(SLM)方案、具備領域知識的多模態模型外,也需更加精細的軟硬體系統整合設計,提供跨模態對齊策略和深度學習方法,讓多模態模型能在不損失訊息的前提下,進一步提升對複雜任務的理解能力,實現模型的精確性、可靠性以及安全性,透過特化訓練降低AI幻覺的風險,並提高安全隱私等,方能靈活應對多樣化的環境挑戰,並且更貼近企業所需。
(本文作者為工研院產科國際所執行產業技術基磐研究與知識服務計畫產業分析師)
 點閱數
點閱數:
1846
